En la sección anterior, vimos como obtener la base de datos Chinook que es la base de datos que usaremos de ahora en adelante en el curso, ya que contiene tablas que se relacionan entre sí, es decir, implementa ya lo que es una base de datos relacional, en la que cada tabla tiene relación con las otras.
En la práctica es muy común que los resultados de las consultas SQL combinen los valores de las columnas de las filas de más de una tabla. Hasta el momento en este curso sólo hemos especificado el nombre de una tabla en la cláusula FROM de una sentencia SELECT. En esta sección y algunas subsecuentes vamos a ver los diferentes tipos de combinación, unión o concatenación de las filas y columnas de dos o más tablas.
En esta sección específicamente veremos la combinación más sencilla que es especificar los nombres de las tablas que combinaremos en la consulta. Debes tener ya abierta la base de datos Chinook y el archivo de sql donde hemos estado escribiendo nuestras sentencias SQL de este curso.
Escribe y ejecuta la siguiente sentencia:
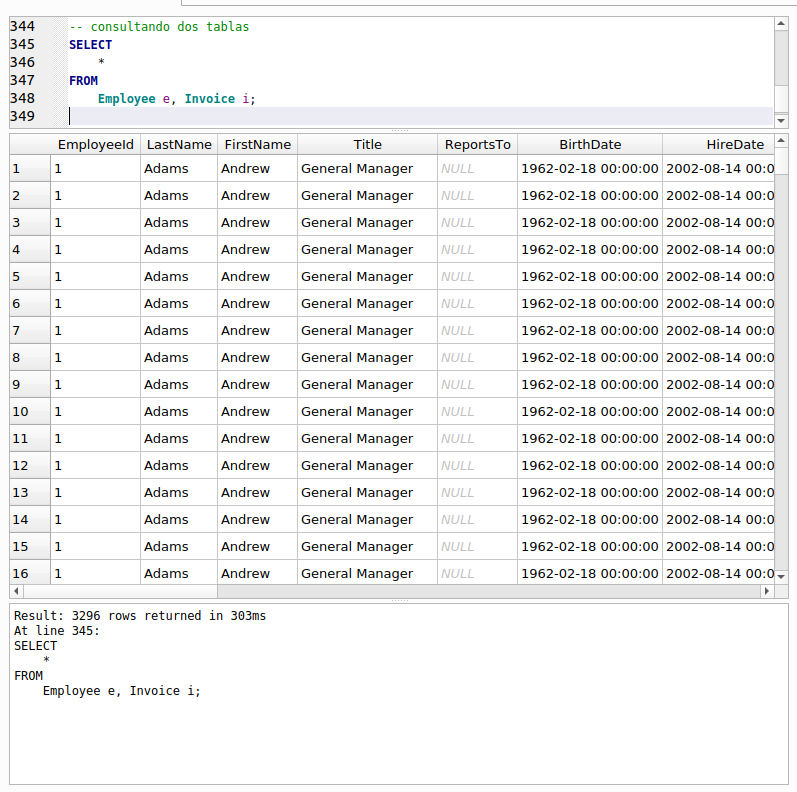
Observa que nos dió como resultado 3296 filas el resultado. Si te deslizas hacia la derecha para ver todas las columnas que arroja esta consulta, verás que primero muestra las columnas de la tabla “Employee” (empleado) y al final las columnas pertenecientes a la tabla “Invoice” (factura). Los valores de las columnas de ambas tablas se han combinado. También puedes observar que los valores de las columnas de la fila de la tabla “Employee” que tiene en su columna “EmployeeId” con valor 1 se repite muchas veces. Si te deslizas hacia abajo irán apareciendo el resto de las filas de la tabla “Employee” pero repetidas muchas veces. Deslízate hasta la fila 413 de los resultados, deberás ver lo siguiente:
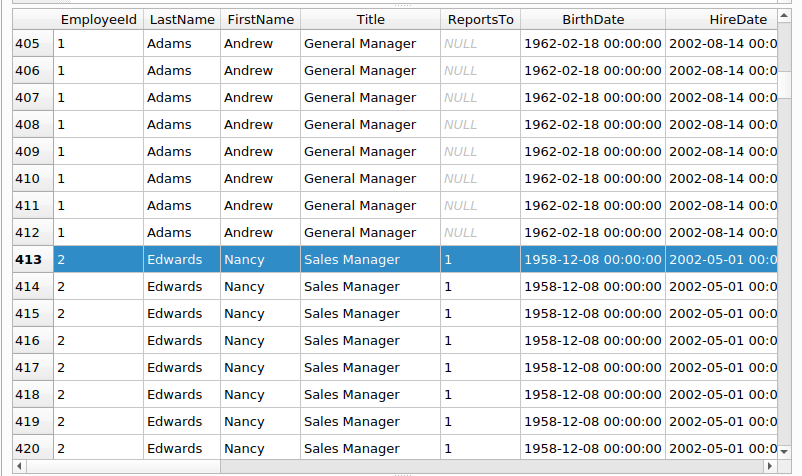
Si observas, a partir de la fila 413, los valores de las columnas que pertenecen a la tabla “Employee” (empleado) dejan de repetirse e inician con otro número de “EmployeeId” o identificador del empleado, en este caso el número 2. La fila de la tabla “Employee” la cual tiene el “EmployeeId” 1, se repitió 412 veces. Ahora, si observas los valores de las columnas de la tabla “Invoice” (factura) que aparecen al final de las filas de la consulta de esas primeras 412 filas que repitió los datos del empleado con “EmployeeId” igual a 1, verás que sus valores no se repiten. ¿Por qué? Bueno, lo que pasa es que cuando se combinan dos tablas como lo hicimos en la sentencia SELECT, se produce lo que se llama un “Producto Cartesiano” de las filas de ambas tablas.
¿Que es un “Producto Cartesiano”? Bueno, es combinar cada uno de los elementos de un primer conjunto con todos los elementos de un segundo conjunto. En nuestra consulta, el primer conjunto lo representa la tabla “Employee” y su elementos vienen siendo cada una de sus filas, el segundo conjunto sería la tabla “Invoice” y sus elementos cada una de sus filas. Al final y al cabo el número resultante de filas de la consulta que ejecutamos, es una simple multiplicación de las filas de la primera tabla, por las filas de la segunda. ¿Recuerdas cómo contar las filas de una tabla? Escribe y ejecuta las siguientes sentencias y anota el resultado:
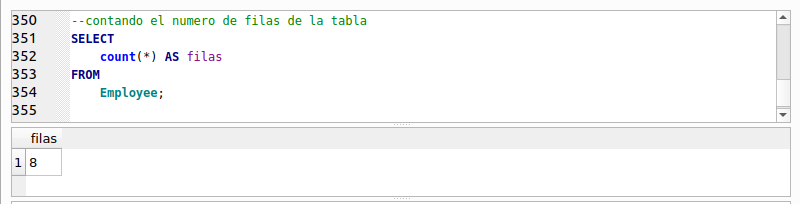
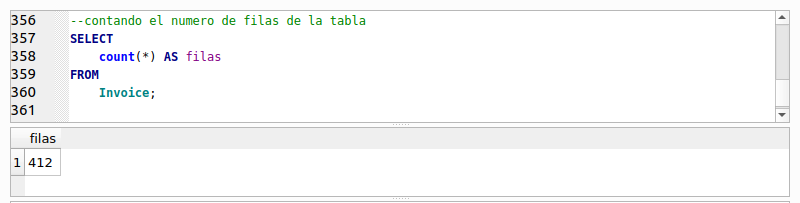
La tabla “Employee” contiene 8 filas y la tabla “Invoice” contiene 412 filas. Si hacemos la multiplicación de 8 X 412 nos dará como resultado 3296. ¡Que es el número de filas que arroja el resultado de nuestra primera consulta! Efectivamente un “Producto Cruzado” es una multiplicación. En una cláusula FROM no sólo se pueden especificar dos tablas, podemos especificar más separándolas por comas. El número de filas resultantes corresponderá a la multiplicación del total de filas de todas las tablas especificadas. En la siguiente práctica veremos un ejemplo.
Vamos a usar varias veces la tabla de empleados, “Employee”, que es la tabla con menos filas (8), en la cláusula FROM para ejemplificar el caso de más de dos tablas. Le daremos un alias distinto a cada especificación de la tabla “Employee”, así mismo, vamos a limitar los campos a mostrar en el resultado a sólo el identificador, el campo “EmployeeId” de cada tabla, especificándole a cada uno un alias para distinguir a que alias de la tabla “Employees” pertenece. Finalmente vamos a ordenar los resultados. Escribe y ejecuta el siguiente ejemplo:
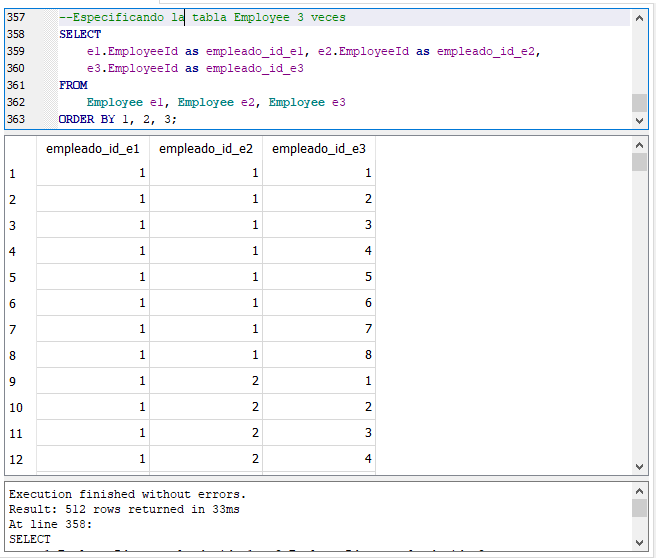
En la consulta le estamos dando diferente alias a cada una de las veces que usamos la tabla “Employee”: “e1”, “e2” y “e3”. Y estamos limitando el despliegue de las columnas para que sólo nos muestre el identificador de cada empleado de cada alias de tabla: “e1.EmployeeId”, “e2.EmployeeId” y “e3.EmployeeId”. Puedes ver el uso de alias en la sección “SQL básico. Funciones sobre cadenas de texto en la parte” en la parte “Usando alias en una sentencia SQL”.
Observa que el número de filas que regresó la consulta es de 512 filas. Recuerda que la tabla “EmployeeId” tiene 8 filas o registros. Si multiplicamos las ocho 8 filas que contiene la tabla “Employee” con alias “e1” por las ocho filas de la tabla “Employee” con alias e2 por las ocho filas de la tabla “Employee” con alias e3 nos dará el total de filas de la consulta: 8 x 8 x 8 = 512.
Navega por los resultados de la consulta y observa los valores en cada columna de cada fila, verás cómo se combina cada uno de los identificadores de la la primera tabla , con cada una de los identificadores de la segunda tabla y esta a su vez con cada uno de los identificadores de la tercer tabla.
Cláusula CROSS JOIN. Combinación o concatenación cruzada de filas.
La cláusula CROSS JOIN se usa en la cláusula FROM de una sentencia SELECT. Tienen exactamente el mismo efecto que la coma (,) en las sentencias que hemos escrito anteriormente. Produce un producto cruzado de las filas de cada tabla. Reemplazaremos las comas por la cláusula CROSS JOIN en la sentencia anterior. Escribe y ejecuta la siguiente sentencia para comprobarlo:
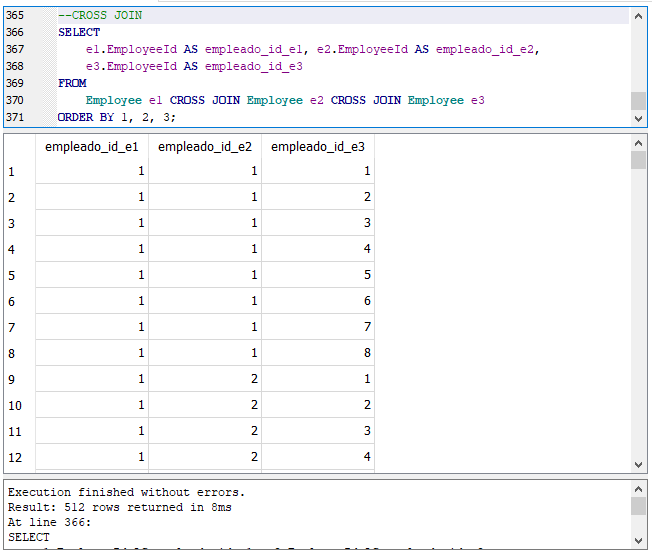
En la sentencia anterior reemplazamos las comas por la cláusula CROSS JOIN. Puedes observar que obtienes las mismas 512 filas y los mismos valores en cada columna y fila. Podemos concluir que con la cláusula CROSS JOIN obtendremos exactamente los mismos resultados que separando cada tabla por una coma (,). Aunque para buenas prácticas y claridad de la sentencia SELECT se recomienda incluir la cláusula CROSS JOIN.
En la siguiente sección, veremos otro tipo de combinación de filas en una sentencia SELECT: la cláusula INNER JOIN.
Recuerda dejar un comentario si tienes alguna duda u observar alguna errata, para mejorar el curso.
¡Hasta la próxima!