Oracle ofrece una versión gratuita o libre de su Base de Datos llamada “Oracle Database XE” (Express Edition o Edición Exprés). Es de uso sin coste, pero tiene sus limitaciones: sólo permite hasta 12 GB de datos (no servirá si tu base de datos es muy grade), 2 GB RAM (no utiliza más memoria RAM que esta), sólo utilizará dos CPU y hasta tres bases de datos “enchufables”.
Sin embargo, resulta muy útil para desarrolladores, científicos de datos, administradores y educadores, ya que cuenta con casi todas las funcionalidades de la Base de Datos Oracle.
Instalar la base de datos gratuita Oracle Database XE en Windows.
Para instalar el software de la base de datos es necesario contar con ciertos requisitos mínimos en el sistema o equipo de cómputo donde se vaya a poner.
Importante: esta guía de instalación presupone que es la primera vez que se instala una Base de Datos Oracle en el equipo destino.
Requisitos del sistema para instalar Oracle Database XE en Windows.
A la fecha de escribir esta entrada, la última versión de Oracle Database XE es la 18.4.0.0.0 (18c). Los requisitos que debe tener el equipo donde se vaya a instalar son:
- Windows 7 al 10 versiones de 64 bit, Profesional, Enterprise o Ultimate. Windows Server 2012, 2012 R2 o 2016 de 64 bits, versiones Estandar, Datacenter, Essentials o Foundation.
- Espacio en disco de al menos 10.5 gigabytes.
- Al menos 2 gigabytes de memoria RAM.
Además, el usuario que instale la aplicación debe ser miembro del grupo de Administradores de Windows.
Instalación de Oracle Database XE.
Es importante decir que para la descarga de los productos de Oracle, es necesario contar con un usuario registrado en su sitio. Si no cuenta ya con un usuario registrado en Oracle, regístrese antes aquí.
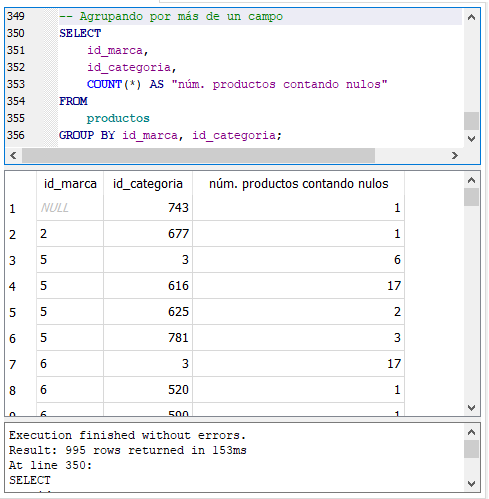
Vaya a la página de descargas del producto https://www.oracle.com/mx/database/technologies/xe-downloads.html y de clic en la liga “Oracle Database 18c Express Edition for Windows x64”, marcada con rojo en la imagen.
Aparecerá la aceptación de licencia. Seleccione el cuadro para aceptar la licencia y activar e botón de descarga. Presione el botón “Download OracleXE184_Win64.zip”:

Si aún no ha ingresado con su cuenta de Oracle, aparecerá la página de inicio de sesión en Oracle. Proporciones el nombre de usuario y su contraseña y oprima “Iniciar sesión”. Si no tine aún una cuenta puede crearla presionando el botón “Crear una cuenta”:
Una vez presionado el botón “Iniciar sesión” iniciará la descarga de un archivo compactado en formato ZIP que contiene el instalador. La descarga puede tardar dependiendo de la velocidad de Internet con la que cuente. El tamaño del archivo es de casi 2 GB.
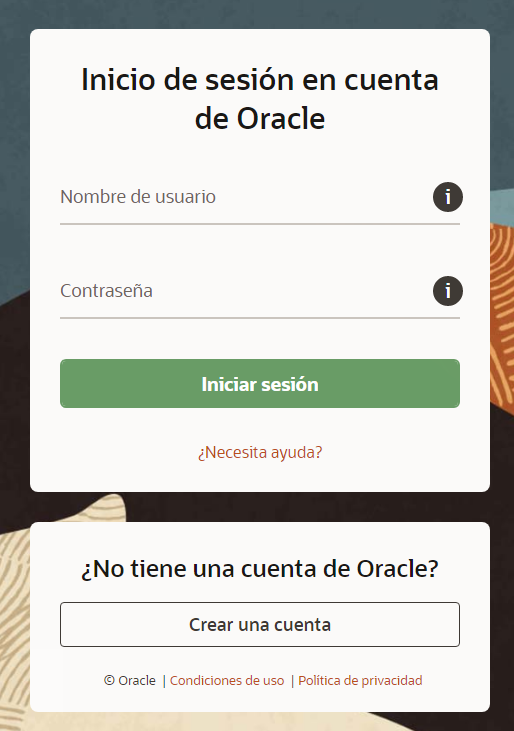
Una vez descargado, descomprima el archivo llamado “OracleXE184_Win64.zip” en una carpeta temporal de su preferencia. Busque y ejecute el archivo “setup.exe” en dicha carpeta.
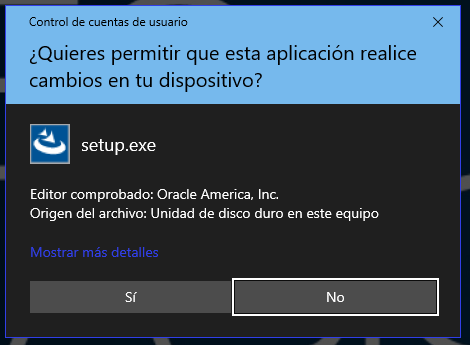
Permita que la aplicación realice cambios en la computadora oprimiendo el botón “Sí” y espere un momento mientras arranca el instalador.
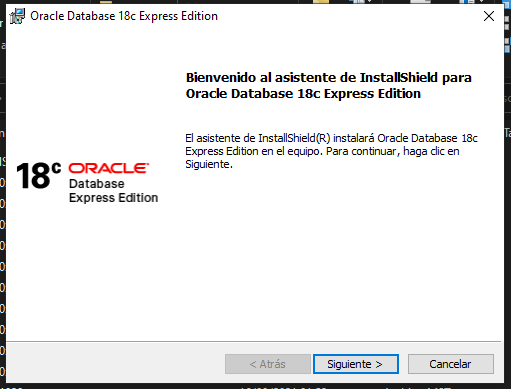
Espere a que se muestre la pantalla de bienvenida del instalador y oprima “Siguiente >”.
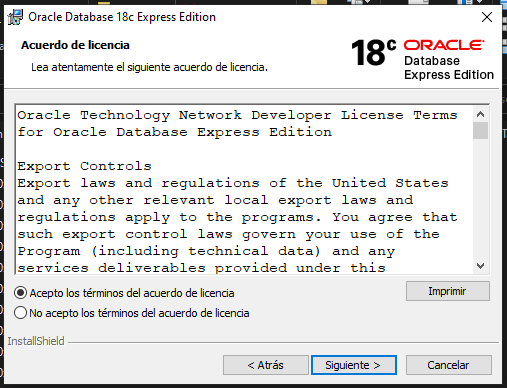
Acepte los términos de licencia seleccionando el círculo “Acepto los términos del acuerdo de licencia” y oprima el botón “Siguiente >”.
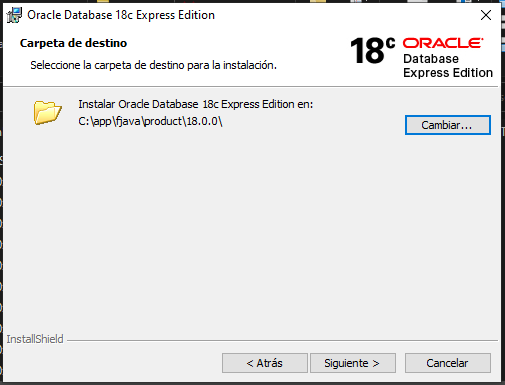
Acepte la carpeta de destino de instalación por defecto o seleccione alguna de su preferencia oprimiendo el botón “Cambiar…”. Presione e botón “Siguiente >”.
Teclee dos veces una contraseña que se usará para las cuentas administrativas de la Base de Datos y oprima “Siguiente >”.
Se mostrará la ventana de resumen de la instalación. Si necesita cambiar oprima “< Atrás”, en caso contrario oprima “Instalar” para iniciar la instalación.
Aparecerá la pantalla de instalando Oraacle Database. La instalación puede llevarse unos minutos. Una vez terminado oprima el botón “Siguiente >”.
Si la instalación resultó exitosa debe aparecer la siguiente ventana:
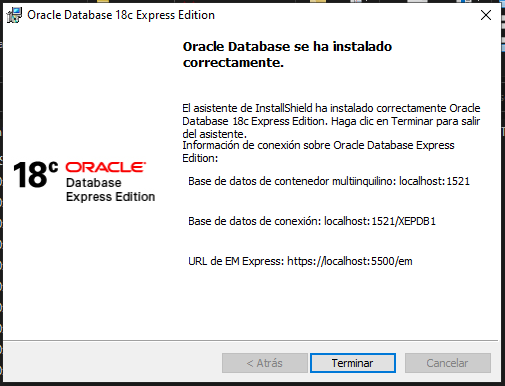
Nos muestra tres datos que hay que anotar:
La dirección del contenedor multiinquilino: localhost:1521.
La conexión a la base de datos: localhost:1521/XEPDB1.
La URL de software EM Express: https://localhost:5500/em.
Presiona “Terminar” para finalizar la instalación.
EM Express es una aplicación web para administración básica de la base de datos, sin embargo ésta aplicación utiliza Adobe Flash Player, que desgraciadamente desde el 31 de Diciembre del 2020 ya no puede ser instalado y por lo tanto la aplicación ya no funciona. En su lugar recomiendo usar SQL Developer.
Instalación del programa SQL Developer para administrar la base de datos.
En esta entrada del blog, puedes encontrar las instrucciones de cómo instalar SQL Developer en tu equipo.
Prueba de conexión a la base de datos mediante SQL Developer.
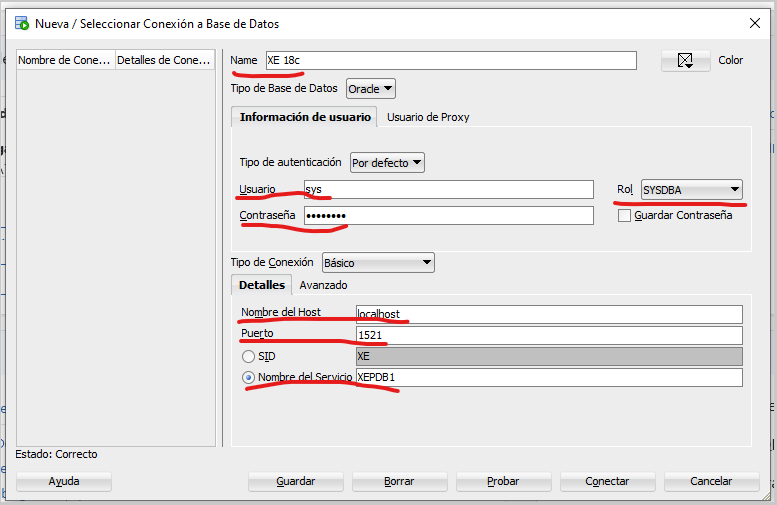
Vamos a utilizar el programa SQL Developer para probar que nuestra base de datos fue instalada correctamente y está en funcionamiento. Abre el programa si aún no lo has abierto y crea una conexión con los datos que nos proporcionó la última pantalla del instalador y que anotamos.
En esta entrada se explica la forma de hacer la conexión a nuestra base de datos recién creada. Si la conexión se crea correctamente significa que nuestra base de datos se instaló correctamente. ¡Felicidades!
¡Hasta pronto!