En la sección anterior vimos como agrupar datos. En esta sección veremos cómo mostrar esos mismos resultados pero en orden.
Combinando las cláusulas GROUP BY y ORDER BY en una sentencia SELECT.
En una sentencia SELECT la cláusula ORDER BY debe aparecer siempre después de la cláusula GROUP BY, recuerde que la primera sirve para mostrar los resultados ordenados y la segunda para agrupar los resultados.
Usaremos una consulta que vimos en la sección anterior:
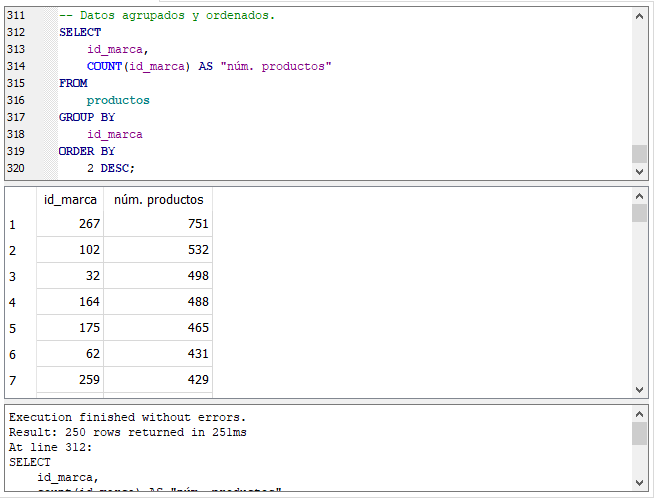
Resultados agrupados en desorden.
En dicha consulta los resultados de la columna “núm productos” aparece en desorden. La modificaremos un poco y agregaremos la cláusula ORDER BY para mostrar un mejor resultado.
Agrupando y ordenando.
Como puede observar en la sentencia, la cláusula ORDER BY que es la encargada de ordenar los resultados, aparece después de la cláusula GROUP BY. Esto es lógico porque GROUP BY necesita conocer los resultados que va a ordenar.
También puedes observar que a diferencia del ORDER BY que usamos en la sección “Cómo ordenar los resultados de una consulta” de este mismo curso, donde especificábamos el nombre de un campo o columna para indicarle por cual de ellos ordenar, aquí usamos un número. ¿Qué representa ese número? Representa el número de la columna de la lista de columnas en la cláusula SELECT numerándolas de izquierda a derecha comenzando por el número 1. En nuestro ejemplo el 2 representa la segunda columna en los resultados, es decir la columna “núm. productos”.
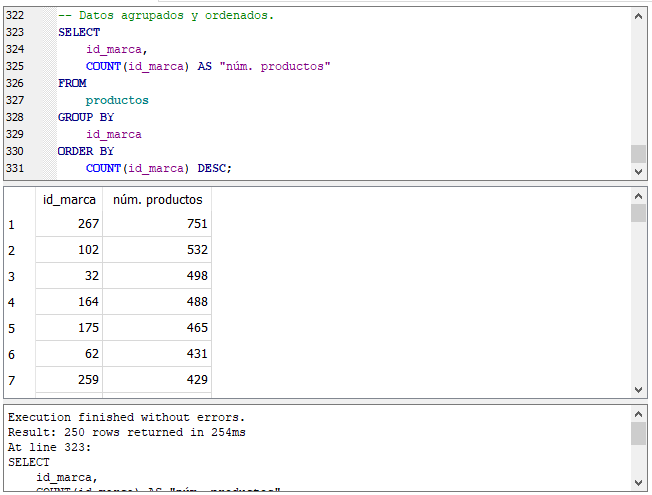
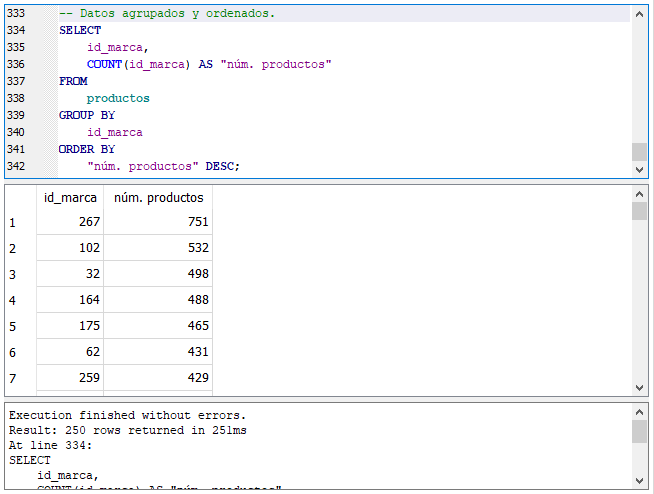
Las siguientes sentencias son equivalentes a la anterior:
Ordenando por el contenido de la columna.
Ordenando por el alias de la columna.
SQLite permite especificar la columna de ordenamiento tanto por el número de columna como vimos en la primera sentencia donde usamos el ORDER BY, por el contenido de la columna, en este caso la función COUNT(), como en el segundo ejemplo o por el alias de la columna, somo se muestra en la última sentencia arriba.
En caso de otros motores de datos, es posible que no soporte todos estos casos. Consulte la documentación específica de cada uno de esos motores de base de datos.
Hasta el momento sólo hemos hecho consultas sobre una tabla, pero en la práctica, las bases de datos relacionales, como su nombre lo indica, trabaja con relaciones, es decir, tablas relacionadas. En la siguiente sección veremos como descargar una base de datos más real, con tablas relacionadas, que nos servirán en las próximas prácticas.
En la sección anterior vimos como resumir datos a través de algunas funciones de SQL de agregación. Por lo general estas funciones se usan o van de la mano con la agrupación de datos. En esta sección veremos como agrupar datos y usar las funciones de agregación para mostrar resultados.
Cómo agrupar los resultados de una consulta SQL.
SQL permite agrupar los resultados de una consulta por una o varias columnas o campos. Para eso usamos la cláusula GROUP BY de la sentencia SQL SELECT.
Cláusula SQL GROUP BY.
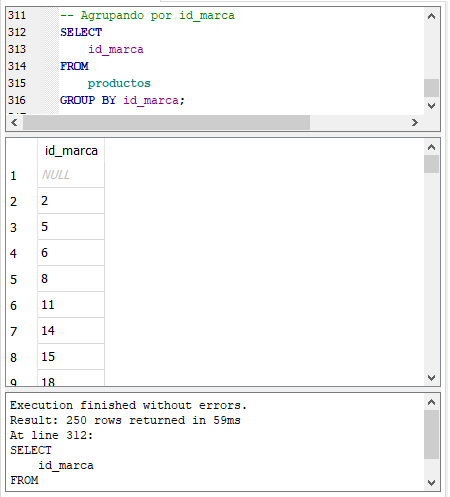
La cláusula GROUP BY agrupa los datos por una determinada columna o columnas. Veamos un ejemplo, para ello, abre la base de datos con la que hemos venido trabajando y abre el archivo sql también. Escribe y ejecuta la siguiente sentencia:
Cláusula ORDER BY.
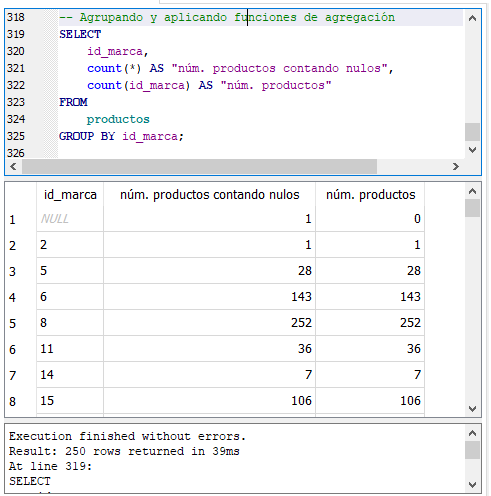
En la sentencia anterior estamos agrupando los resultados por la columna id_marca, el resultado da los distintos valores de la columna id_marca. Es decir que esta agrupando por los distintos valores de la columna id_marca. Esta consulta no tiene mucho valor práctico, solo nos muestra los distintos valores que contiene id_marca y nos dice que hay 250 filas o valores distintos de id_marca. Apliquemos ahora las funciones de agregación que vimos en la sección anterior:
GROUP BY con funciones de agregación.
La consulta anterior nos muestra el id_marca, el número de productos que hay de cada id_marca contando los valores nulos de id_marca y por último, cuántos productos de cada id_marca hay, sin tomar en cuenta los valores nulos de id_marca. Es por eso la diferencia en la primera fila la cual tiene el valor nulo (null) en id_marca, COUNT(*) regresa 1 porque cuenta todas las filas que contienen nulo (null) en la columna id_marca , mientras que COUNT(id_marca) cuenta los valores de id_marca ignorando los de valor nulo (null) lo que da como resultado cero.
No sólo podemos usar el campo por el que estamos agrupando en las funciones de agregación, podemos usar cualquiera de los otros campos. Escribe y ejecuta el siguiente ejemplo:
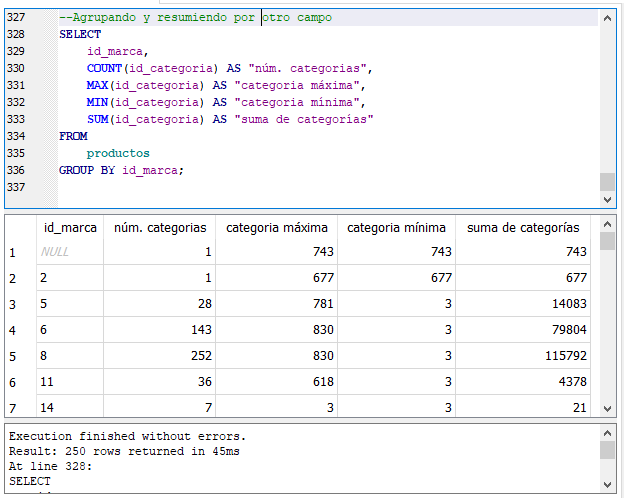
GROUP BY y funciones de agregación.
En la sentencia anterior, seguimos agrupando las filas por la columna id_marca, sin embargo, estamos aplicando las funciones de agregación al campo o columna id_categoria. ¿Que significan los resultados? Bueno, en el caso del grupo de id_marca con valor 5, el grupo cuenta con 28 filas con id_categoria no nulas, la id_categoria con el valor máximo o más alto de ese grupo es 781, la id_categoria con el valor menor de ese grupo es 3 y la suma de los valores de id_categoria de ese grupo da 14,083. Y así sucesivamente para cada grupo diferente de id_marca.
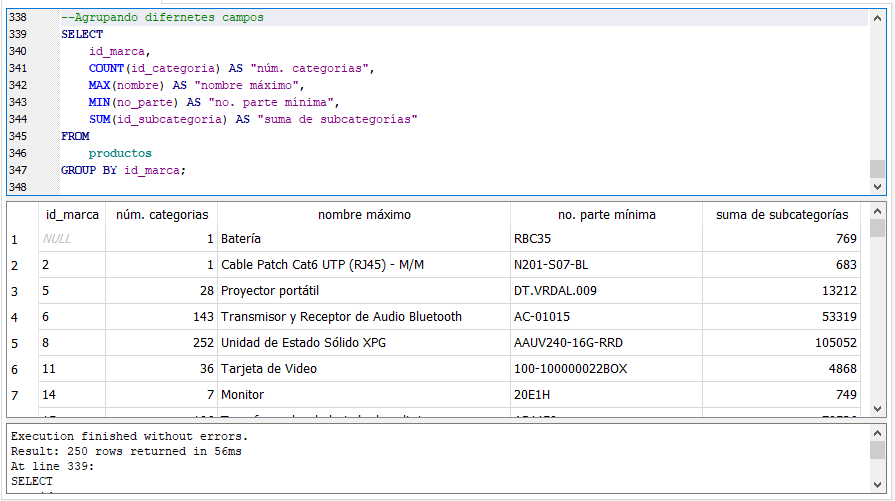
Las funciones de agregación no se tienen que aplicar todas a una misma columna, pueden aplicarse a distintas columnas:
Aplicando funciones de agregación a varias columnas.
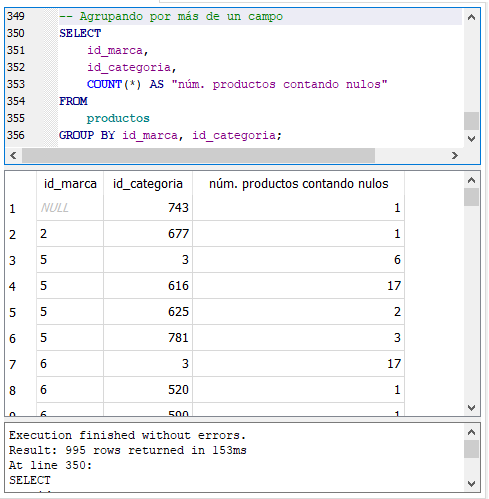
También es posible agrupar por más de un campo:
Agrupando por más de un campo o columna.
En la sentencia anterior estamos agrupando por dos columnas: id_marca e id_categoria. Según las filas resultantes, existen 995 combinaciones diferentes de id_marca-id_categoria, es decir 995 grupos diferentes. La tercera columna de los resultados nos muestra cuantas filas o registros, que en este caso representan productos, hay en cada grupo distinto de id_marca-id_categoria. Por ejemplo, decimos que hay 6 productos o filas que tienen en su columna id_marca igual el valor 5 y el calor 3 en su columna id_categoria y así sucesivamente.
En la próxima sección vamos a combinar las cláusulas ORDER BY y GROUP BY para mostrar resultados más presentables. ¡Hasta la próxima!
SQL cuenta con funciones que permiten resumir en un sólo dato los valores de una columna de todas o algunas de las filas de una tabla. A estas funciones se les conoce como funciones de agregación (“aggregate functions” en inglés). Para hacer las siguientes prácticas, vamos a abrir y a usar la base de datos que hemos estado usando en este curso básico y nuestro archivo de scripts sql.
Funciones SQL de agregación.
Las funciones de agregación trabajan con un conjunto de valores de una columna y regresan un sólo valor. Casi todas ellas ignoran los valores NULOS (null) a excepción de una función que veremos enseguida. Cada motor de base de datos implementan sus propias funciones de agregación y su propia sintaxis, veremos las más comunes entre las distintos motores y que la implementa SQLite.
Función SQL de agregación COUNT()
Esta función cuanta o regresa el número de elementos que existen en un grupo de datos, de acuerdo a la sintaxis empleada, puede incluir los elemento con valor NULO (null) o no. Veamos estas dos diferentes sintaxis:
Sintaxis: COUNT(*) o COUNT([DISTINCT] expresión)
Los corchetes, en la sintaxis, se refiere a que la palabra que contiene es opcional, puede o no puede escribirse. Si se escribe la palabra reservada DISTINCT, la función COUNT() sólo contará los elementos con valores distintos, ignorará los valores duplicados.
Cuando se usa el asterisco (*) la función cuenta todas los filas aún cuando sus elementos tengan valor NULO (null). Cuando se usa una expresión, que por lo general es un nombre de una columna o campo o alias, sólo contará aquellos elementos que tengan valores distintos a NULO. Veamos un ejemplo:
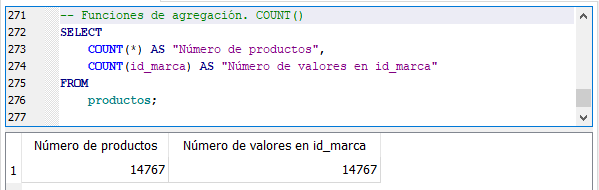
Función COUNT().
El primer uso de la función COUNT(*) regresa un número que representa el total de filas de la tabla “productos” mientras que COUNT(id_marca) regresa el total de valores no nulos que tiene el campo id_marca. En este caso, los resultados son iguales, ambas funciones regresan el número 14,767.
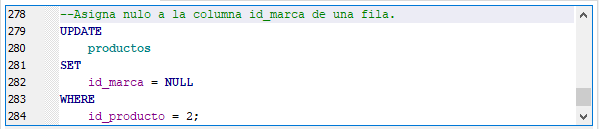
Vamos a actualizar una fila de la tabla “productos” poniendo el valor nulo a la columna id_marca a la fila con el valor 2 en id_producto. Para eso ejecuta la siguiente sentencia:
Actualiza campo a nulo de una fila.
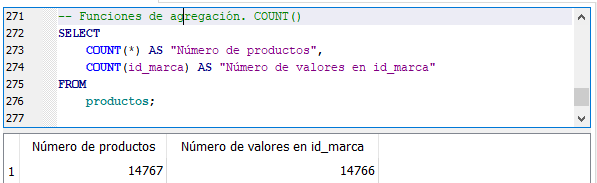
Vuelve a ejecutar la sentencia COUNT() inicial:
Función COUNT() con valores nulos.
Ahora los resultados de ambas funciones COUNT() son diferentes. ¿Por qué? Porque como dijimos antes, COUNT(*) cuanta el total de fila del grupo, en este caso de toda la tabla y, COUNT(id_marca) cuenta los valores no nulos del campo id_marca. Y ya existe un valor nulo en ese campo con ls sentencia UPDATE que ejecutamos anteriormente.
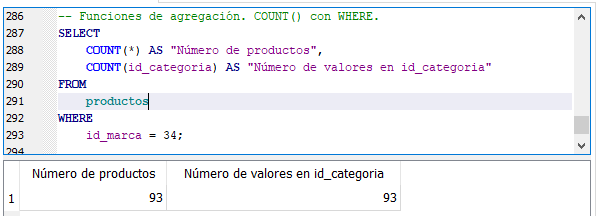
Si a la sentencia SELECT le agregamos un filtro o condición a través de la cláusula WHERE las funciones COUNT() sólo se limitarán a contar las filas o elementos de ese grupo. Veamos un ejemplo:
Función COUNT() con WHERE.
La sentencia anterior limita las filas a sólo aquellas que su marca sea igual a 34. Las funciones COUNT() se limita a contar solo las filas que cumplan con esa condición. en ese caso, el resultado de ambas funciones es 93, debido a que dentro de los productos con marca igual a 34 no hay valores nulos en su campo id_categoria.
Ahora incluiremos la palabra reservada DISTINCT dentro de la función COUNT(). Veamos el ejemplo:
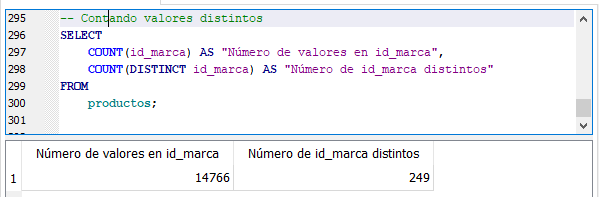
Contando valores distintos.
En la segunda forma de la función COUNT() que incluye la palabra DISTINCT sólo cuenta los valores distintos de la columna id_marca que existen en la tabla “productos”. Quiere decir que de los 14,766 valores no nulos que contiene la columna id_marca sólo hay 249 valores distintos.
Funciones SQL de agregación AVG(), MAX(), MIN() y SUM().
Las funciones de agregación AVG() y SUM() sólo aceptan expresiones numéricas, MAX() y MIN() aceptan tanto expresiones de texto como numéricas.
La función AVG() obtiene el promedio de los valores de una columna. SUM(), MAX() y MIN() obtienen la suma, el valor máximo, y valor mínimo de los valores de una columna respectivamente. Estás funciones sólo tomarán en cuanta los valores no nulos. Al igual que la función COUNT(), estas funciones aplican sobre un grupo de filas o toda la tabla si la sentencia SELECT tiene o no tiene una condición o filtro. Veamos el siguiente ejemplo:
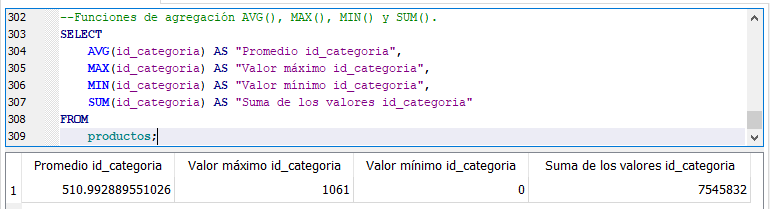
Funciones AVG(), MAX(), MIN() y SUM().
En el ejemplo anterior obtenemos el promedio, valor máximo, valor mínimo y la suma de los valores de la columna o campo id_categoria de todas las filas de la tabla “productos”, ya que no existe existe una condición en la sentencia SELECT que limite el número de filas. Como ejercicio escribe una sentencia SELECT que contenga una cláusula WHERE que limite las filas, por medio del campo id_marca.
En la próxima sección veremos como agrupar datos con SQL mediante una sentencia SQL. ¡Hasta la próxima!