Para realizar consultas SQL a una base de datos Oracle necesitamos un programa cliente. Por defecto, cuando se instala el motor de la base de datos Oracle en un equipo, se instala ahí mismo un programa cliente llamado SQL Plus y en ocasiones el Oracle SQL Developer.
El primero se ejecuta en un ambiente de “consola” mientras que el segundo en un ambiente gráfico. Oracle SQL Developer necesita tener instalado Java para poder funcionar. En esta entrada puedes ver cómo instalar SQL Developer en Windows.
Crear una conexión a Oracle con SQL Developer.
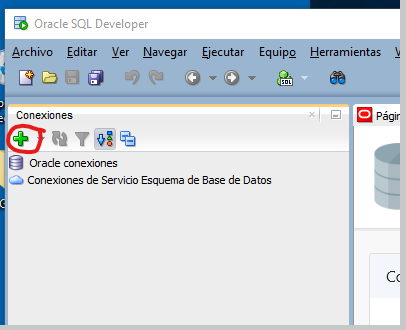
Abre SQL Developer y en la sección “Conexiones” presiona el botón “Nueva conexión..” para abrir el diálogo “Nueva / Seleccionar Conexión a Base de Datos”.
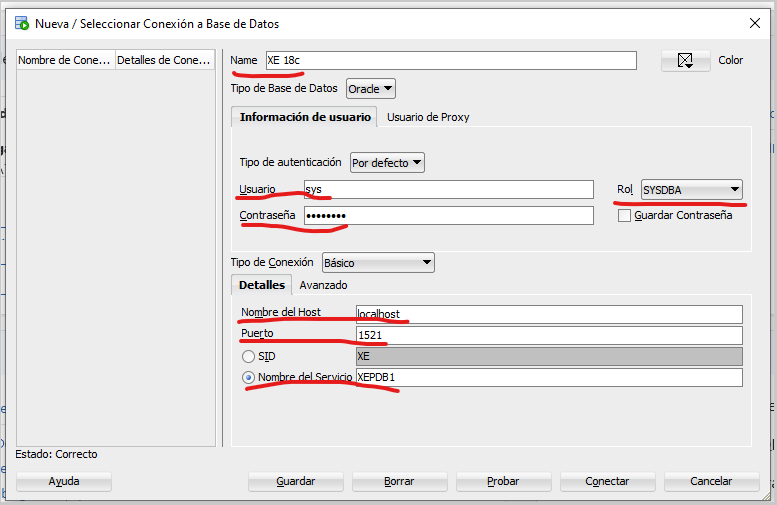
En el diálogo proporciones los datos que se piden:
En el campo “Name” ingrese un nombre con el que identificará la conexión, ejemplo “XE 18c”.
En el campo “Usuario” capture un nombre de usuario ya existente en la base de datos y con permisos de conexión, ejemplo “sys”.
En la lista de opciones “Rol” seleccione el rol con el que se conectará el usuario, si es un usuario normal se deja la opción “valor por defecto”, en este ejemplo, como me conectaré con el usuario administrador “sys” seleccionaré el Rol “SYSDBA”.
En el campo contraseña, ingrese la contraseña.
En “Nombre de Host” capture el nombre de la computadora en la red donde se encuentra instalada la Base de Datos Oracle o la dirección IP. En mi caso dejaré “localhost” ya que la base de datos se encuentra en la misma máquina donde instalé SQL Developer.
En “Puerto” capture “1521”, que es el puerto por defecto de conexión de toda Base de Datos Oracle. Pregunte a su administrador si le asignó otro número de puerto.
Seleccionamos la opción “SID”, si su base de datos maneja SID o “Nombre del Servicio” si su base de datos está configurada como un servicio.
Capture ya sea el nombre del SID o el nombre del servicio asignado a la base de datos. En el ejemplo, en mi caso selecciono “Nombre del Servicio” y capturo el nombre del Servicio “XEPDB1”.
Capture la información según sus datos de conexión. Ejemplo de mi conexión:
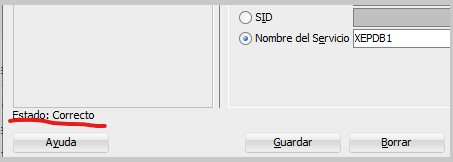
Oprima el botón “Probar” para hacer una prueba de conexión. Debajo de la lista de conexiones, en el mismo diálogo debe aparecer el mensaje “Estado: Correcto” indicando que la prueba de conexión se realizó exitosamente.
Si es así presione el botón “Guardar” para sólo guardar la conexión o “Conectar” para conectar y guardar. El diálogo se cierra y en área de conexiones debe aparecer la conexión recién creada.
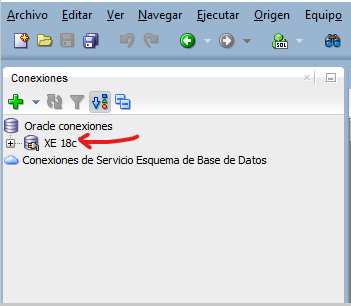
La conexión se conservara permanentemente aún cunado SQL Developer se cierre. La próxima vez que lo ejecute, la conexión seguirá ahí.
Espero y les sea útil esta entrada. ¡Hasta la próxima!